
Want to do something cool this week? Download Cursor and run the free research preview of GPT-5.3-Codex-Spark in the low, medium, high, and extra-high effort modes.
OpenAI positions GPT-5.3-Codex-Spark as their first model intentionally built for real-time coding in Codex. The announcement says it is designed to feel near-instant, delivering more than 1000 tokens per second while still being strong at real-world coding tasks. It uses a 128k context window and is currently text-only.
OpenAI also points out that real-time coding speed is not just a model trait. They reworked the request-response pipeline too, including persistent WebSockets and other stack-level latency improvements. According to the post, these changes reduce per-client roundtrip overhead by 80%, per-token overhead by 30%, and time-to-first-token by 50%.
The hardware behind it#
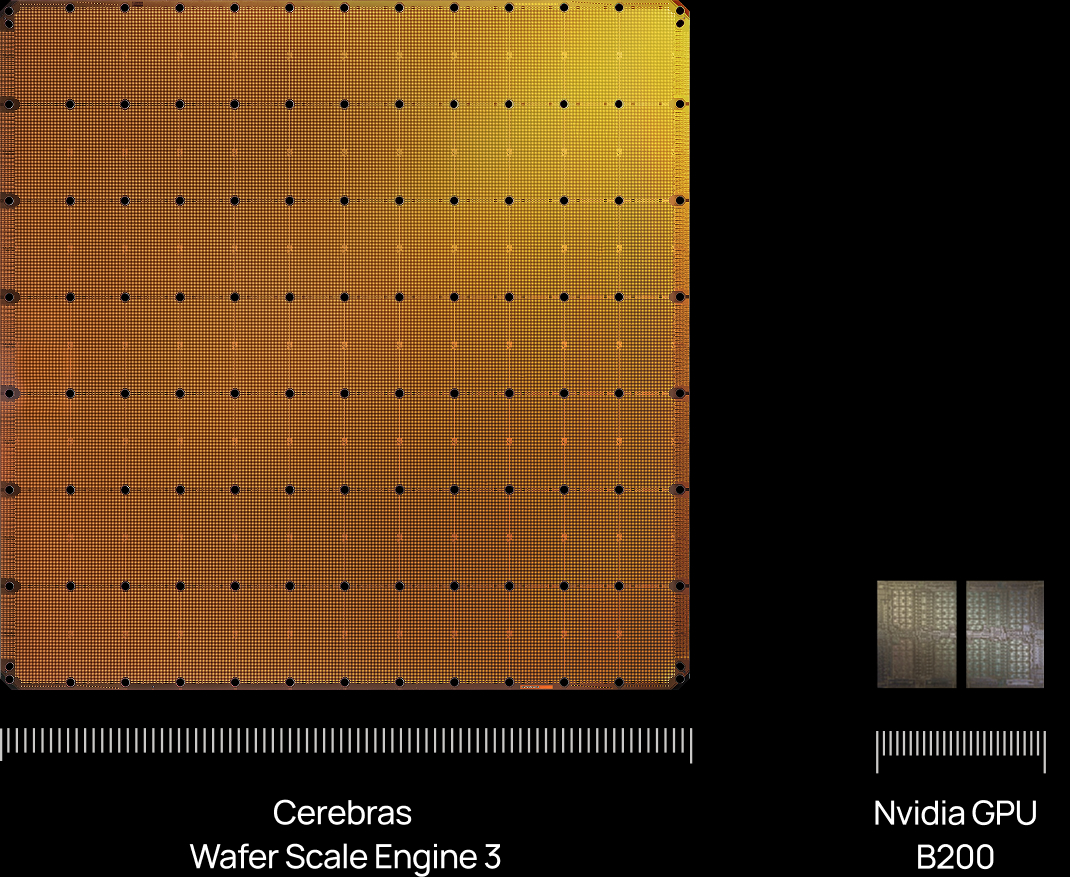
Codex-Spark is currently running on Cerebras hardware as part of OpenAI’s partnership with them. The core piece is the new Wafer Scale Engine 3 (WSE-3).
Cerebras describes the chip as the world’s largest AI processor for training and inference.
From the source material:
- WSE-3 has 46,255 mm² and 4 trillion transistors
- It provides 125 petaflops of AI compute through 900,000 AI-optimized cores
- It claims 19× more transistors and 28× more compute than NVIDIA's B200
Mixed reactions#
Not everyone is sold. Some people question the usefulness of ultra-fast models on Reddit. Some are impressed.
Personally? Using an ultra fast model is INCREDIBLY addictive. And making small changes to your codebase that don't require a ton of validation (for example iterating on small UI changes) is fantastic. That is exactly how I first got converted with the free research preview of grok-code-fast-1.
Comments